
Home > Information > News
#News ·2025-01-09


Translator | Bugatti
Review | heavy building
In recent years, we have witnessed two recurring trends: the release of increasingly powerful Gpus and the proliferation of large language models (LLMS) with billions, if not trillions, of parameters and extended context Windows. Many businesses are taking advantage of these LLMS, either fine-tuning or using RAG to build applications with domain-specific knowledge and deploy them on dedicated GPU servers. Now when it comes to deploying these models on the GPU, one thing to note is the model size, that is, the space required to load the model into the GPU memory (for storing parameters and context tokens) is simply too large compared to the memory available on the GPU.
There are ways to reduce the model size by using optimization techniques such as quantization, pruning, distillation, and compression. But if you notice the following comparison table of the latest GPU memory and space requirements for the 70B model (quantified by FP16), it's almost impossible to handle multiple requests at the same time, or in some Gpus, the model won't even fit into memory.
GPU |
FP16 (TFLOPS) Tape sparsity |
GPU Memory (GB) |
B200 |
4500 |
192 |
B100 |
3500 |
192 |
H200 |
1979 |
141 |
H100 |
1979 |
80 |
L4 |
242 |
24 |
L40S |
733 |
48 |
L40 |
362 |
48 |
A100 |
624 |
80 |
This is all FP16 quantization that has been applied, resulting in some loss of precision (which is usually acceptable in many common use cases).
model |
Parameter required KV cache (FP16) |
Llama3-8B |
16GB |
Llama3-70B |
140GB |
Llama-2-13B |
26GB |
Llama2-70B |
140GB |
Mistral-7B |
14GB |
This brings us to the background of this blog post, which is how enterprises can run large LLM models with billions or trillions of parameters on these modern data center Gpus. Is there a way to split these models into smaller parts and run only the parts you need right now? Or can we allocate parts of the model to different Gpus? In this blog post, I will attempt to answer these questions with a range of methods currently available to perform inference parallelism, and try to highlight some of the tools/libraries that support these parallel methods.
Inference Parallelism aims to distribute computational workloads of AI models (especially deep learning models) across multiple processing units, such as Gpus. This allocation speeds up processing, reduces latency, and can handle models that exceed the memory capacity of a single device.
Four main methods have been developed to implement inference parallelism, each with its own advantages and applications:
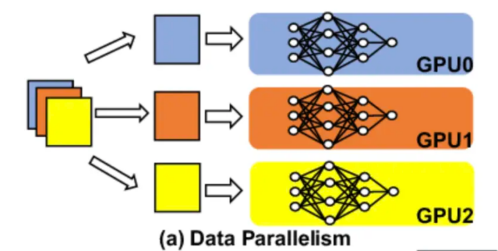
In terms of data parallelism, we deploy multiple copies of the model on different Gpus or GPU clusters. Each copy of the model handles user requests independently. As a simple analogy, this is like having multiple copies of a microservice.
Now, a common question might be how does it solve the problem of model size loading into GPU memory, and the short answer is it can't. This method is only recommended for smaller models that can fit into GPU memory. In this case, we can use multiple copies of the model deployed on different GPU instances and assign requests to different instances, thus providing enough GPU resources for each request and also increasing the availability of the service. This will also improve the overall request throughput for the system because there are now more instances to handle the traffic.
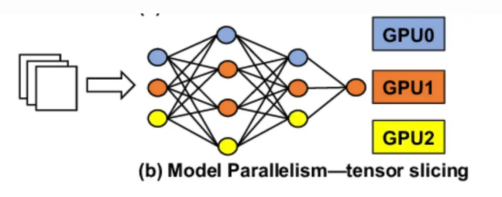
In tensor parallelism, we split each layer of the model onto a different GPU. A single user request is shared across multiple Gpus, and the results of each request's GPU calculations are reassembled through a GPU-to-GPU network.
To better understand tensor parallelism, as the name suggests, we split the tensor into pieces along specific dimensions such that each device holds only 1/N pieces of the tensor. Use this partial block to perform calculations to obtain partial output. These partial outputs are collected from all devices and then combined.
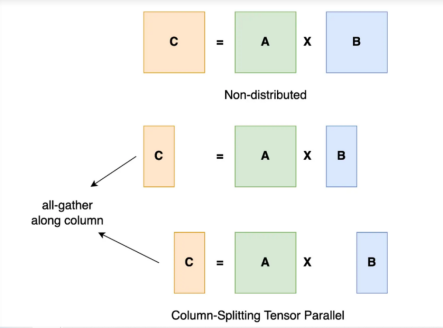
As you may have noticed, the bottleneck in tensor parallelism performance is the GPU-to-GPU network speed. Since each request will be calculated on a different GPU and then combined, we need a high-performance network to ensure low latency.
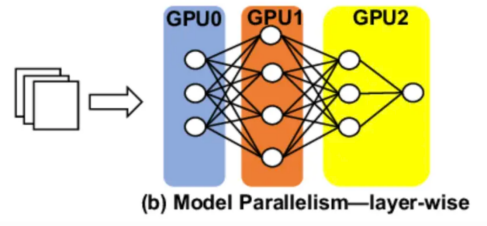
In terms of pipeline parallelism, we assign a set of model layers to different Gpus. Layer-based partitioning is the basic method in pipeline parallelism. The layers of the model are grouped into successive blocks, forming stages. This partitioning is usually done vertically through the architecture of the network. Computational balance is a key consideration. Ideally, each stage should have roughly equal compute loads to prevent bottlenecks. This often requires grouping layers of varying complexity to achieve balance. Memory usage optimization is another key factor. Stages are designed to meet the memory limits of a single device while maximizing utilization. It is also important to minimize communication overhead. The purpose of partitioning is to reduce the amount of data transferred between stages, as inter-device communication can be a serious performance bottleneck.
So, for example, if you deploy a 32-layer LLaMA3-8B model on four GPU instances, you can split and allocate eight layers of the model on each GPU. The processing of requests occurs sequentially, with the computation starting with one GPU and continuing to the next GPU via peer-to-peer communication.
Again, since multiple GPU instances are involved, the network can become a bottleneck if we don't have high-speed network communication between Gpus. This parallelism can increase the throughput of the GPU because each request will require fewer resources from each GPU and should be easy to obtain, but it ends up increasing overall latency because requests are processed sequentially and any latency in terms of GPU calculations or network components causes latency to spike overall.
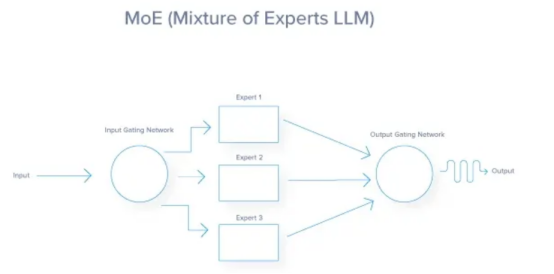
Expert parallelism is often implemented as expert blending (MoE), a technique that allows the efficient use of large models in reasoning. It does not solve the problem of loading the model into GPU memory, but provides an option to process a broad functional model of the request based on the request context. In this technique, the model is divided into several expert subnets. Each expert is typically a neural network trained to deal with a specific type of input or subtask within a broader problem domain. The gated network decides which expert to use for each input. For any given input, only a subset of experts are activated. Different experts can be assigned to different Gpus. Router/gated networks and active experts can run in parallel. Inactive experts do not consume computing resources. This greatly reduces the number of parameters that each request must interact with, as some experts are skipped. But as with tensor parallelism and pipeline parallelism, the overall request latency relies heavily on the GPU-to-GPU communication network. After expert processing, the request must be reconstructed back to its original GPU, which constitutes high network communication through the GPU-to-GPU interconnect structure.
This approach makes better use of the hardware than tensor parallelism because you don't have to split the operation into smaller pieces.
Below is a summary and comparison of the approaches we discussed. You can use it as a reference when you plan to choose an approach for your use case.
aspect |
Data parallelism |
Tensor parallelism |
Pipeline parallelism |
Expert parallel |
Basic concept |
Split input data across multiple devices |
Split a single tensor/layer on the device |
Split the model into sequential stages on the device |
The model is segmented into multiple expert subnetworks |
Working principle |
The same model is copied to each device, processing different data blocks |
A single layer/operation is distributed across multiple devices |
Different parts of the model pipeline are on different devices |
The router selects a specific expert for each input |
Parallel unit |
Input lot |
Single tensor/layer |
Model stage |
Experts (subnetwork) |
expandability |
Good scalability relative to batch size |
Good scalability for very large models |
Good scalability for deep models |
The scalability is good for wide models |
Memory efficiency |
Low (on each device There is a standard model) |
High (on each device Only each layer In part) |
High (on each device Just one part of the model Points) |
Medium to high (experts assigned on equipment) |
Communication overhead |
low |
Medium to high |
Low (only adjacent Stages Between) |
Medium (router communication
|

2025-02-17

2025-02-14

2025-02-13

抖音二维码


微信公众号

QQ群:

小红书二维码
13004184443
Room 607, 6th Floor, Building 9, Hongjing Xinhuiyuan, Qingpu District, Shanghai
gcfai@dongfangyuzhe.com

WeChat official account
friend link


13004184443
立即获取方案或咨询
top







