
Home > Information > News
#News ·2025-01-07


The lead author of the paper is from a research team at the University of Toronto, Snap Inc., and UCLA. The first authors are Hanwen Liang, a PhD student at the University of Toronto, and Junli Cao of Snap Inc., who focus on video generation and 3D/4D scene generation and reconstruction to create more realistic, high-quality 3D and 4D scenes. Team members look forward to communicating and cooperating with more like-minded researchers.
The ability to perceive and imagine a three-dimensional world from a single image is a natural part of human cognition. We can intuitively estimate the distance, shape, and guess the geometry of the occluded area. However, entrusting this complex cognitive process to machines is challenging. Recently, a research team from the University of Toronto, Snap Inc., and UCLA introduced a new model, Wonderland, which is capable of generating high-quality, wide-range 3D scenes from a single image, making a breakthrough in the field of single-view 3D scene generation.


Traditional 3D reconstruction techniques often rely on multi-view data or per-scene optimization, and are prone to distortion when dealing with background and invisible areas. To solve these problems, Wonderland innovatively combines video generation models and large-scale 3D reconstruction models to achieve efficient and high-quality large-scale 3D scene generation:
Accurate viewing Angle control for video generation based on a single image and camera condition:
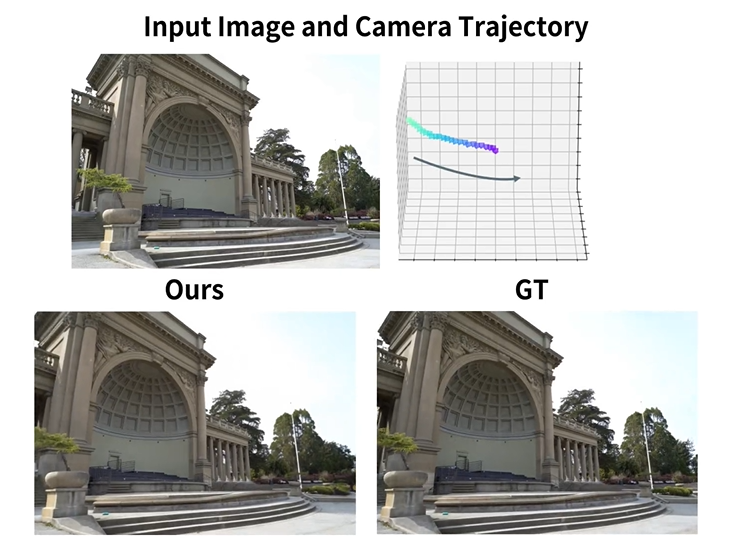


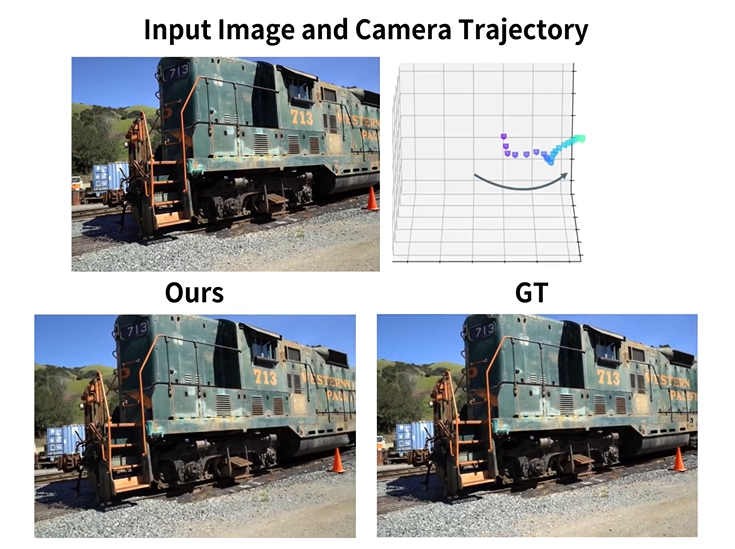
The Camera-guided video generation model can accurately follow the conditions of the trajectory and generate high-quality 3D-geometry videos with strong generalization, which can follow a variety of complex trajectories and is suitable for various styles of input images.
Some more examples:
Different input pictures, same three camera tracks, generated video:




Given the input picture and multiple camera tracks, the generated video can explore the scene in depth:




Based on a single image, Wonderland can generate high-quality, expansive 3D scenes with LaLRM:
(The following shows the results from the created 3DGS Rendering)




Based on a single map and multiple camera tracks, Wonderland can deeply explore and generate high-quality, expansive 3D scenes:
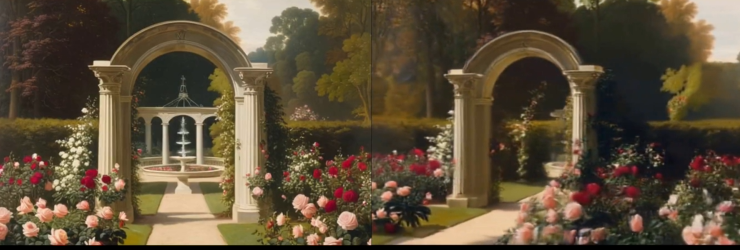



The main characteristics of Wonderland are its precise perspective control, excellent scene generation quality, generation efficiency and wide applicability. The experimental results show that the model outperforms the existing methods on multiple data sets, including view control of video generation, visual quality of video generation, geometric consistency of 3D reconstruction, image quality of rendering, and end-to-end generation speed.
Wonderland provides a new solution for the creation of video and 3D scenes. In the fields of architectural design, virtual reality, film and television special effects and game development, the technology has shown broad application potential. Through its precise video pose control and wide-angle, high-definition 3D scene generation capabilities, Wonderland is able to meet the demand for high-quality content in complex scenes and bring more possibilities to creators.
Despite the model's excellent performance, the Wonderland research and development team knows that there are still many directions to improve and explore. For example, further optimizing the adaptation ability of dynamic scenes and improving the restoration degree of real scene details are the focus of future efforts. It is hoped that through continuous improvement and improvement, this research and development idea will not only promote the progress of single-view 3D scene generation technology, but also contribute to the widespread popularity of video generation and 3D technology in practical applications.

2025-02-17

2025-02-14

2025-02-13

抖音二维码


微信公众号

QQ群:

小红书二维码
13004184443
Room 607, 6th Floor, Building 9, Hongjing Xinhuiyuan, Qingpu District, Shanghai
gcfai@dongfangyuzhe.com

WeChat official account
friend link


13004184443
立即获取方案或咨询
top







