
Home > Information > News
#News ·2025-01-06


Fine-tuning large model data privacy may be compromised?
Recently, a research team from Huacke and Tsinghua University jointly proposed a member inference attack method that can effectively utilize the powerful generation ability of large models to detect whether a given text belongs to a fine-tuned dataset of large models through a self-tuning mechanism.
NeurIPS24, Membership inference attacks against fine-tuned large language models via self-prompt calibration, A member inference attack algorithm SPV-MIA based on self-correcting probability fluctuation is proposed, which improves the attack accuracy to more than 90% for the first time in the fine-tuned large model scenario.

Membership Inference Attack is a common method of privacy attack against machine learning models. This attack can determine whether a particular input data is part of the model training data set, resulting in the privacy of the training data set being compromised. For example, the attack determines whether a user's information has been used for model training to infer whether the user has used the corresponding service. In addition, the attack can also be used to identify unauthorized training data, providing a promising solution for copyright authentication of machine learning model training sets.
Although the attack in the traditional machine learning field, including classification, segmentation, recommendation and other models have made a lot of research progress and rapid development. However, the member inference attack method for Large Language Model (LLM) has not made satisfactory progress. Due to the large scale data set of large models, high generalization and other characteristics, the accuracy of member inference attacks is limited.
Due to the strong fitting and generalization ability of the large model itself, the algorithm integrates a Self-Prompt method, which prompts the large model to generate a correction data set that approximates the training set in distribution, so as to obtain better correction performance of member inference scores. In addition, based on the memory phenomenon of the large model, the algorithm further designs a Probabilistic Variation member inference attack score to ensure the stable discrimination performance of the attack algorithm in the real scene. Based on the above two methods, the attack algorithm realizes the precise member inference attack in the fine-tuning large model scenario, and promotes the future research on data privacy and copyright authentication of large model.
The existing methods of member inference attack against language models can be divided into two paradigms: Reference-based and Reference-free. The uncorrected member inference attacks assume that the text data in the training set has a higher generation probability (i.e. a lower Loss on the target language model), so the uncorrected attack paradigm can simply identify the text in the training set by judging whether the sample generation probability is higher than the preset threshold.

△Reference-free Indicates the flow chart of uncorrected member inference attacks
Correction-based member inference attacks suggest that some commonly used texts may have Over-representative features, that is, they naturally tend to have a higher probability of being generated. Therefore, this attack paradigm uses a Difficulty Calibration method, which assumes that the text of the training set will achieve a higher generation probability on the target model than the corrected model, and selects the text with a higher generation probability by comparing the generation probability difference between the target large model and the corrected large model.

△Reference-based Indicates the flow chart of member inference attacks based on correction
However, the two existing member inference attack paradigms rely on two assumptions that do not hold in real-world scenarios: 1) a correction data set with the same data distribution as the training set can be obtained, and 2) there is overfitting of the target large language model. As shown in FIG. (a) below, we used three different calibration datasets, which were distributed, in the same domain, and unrelated to the target model training set, to fine-tune the calibration model. Uncorrected attack performance is consistently low and independent of the source of the data set. For correction-based attacks, as the similarity between the corrected data set and the target data set decreases, the attack performance shows a catastrophic decline. As shown in Figure (b) below, both existing attack paradigms can only achieve good attack performance in large models that present fitting phenomena. Therefore, the existing paradigms can only achieve discrimination performance close to random guessing in real scenarios.

▷ The discrimination performance of the existing attack paradigms in real scenarios is close to random guessing
To address these two challenges, we propose a Self-calibrated Probabilistic Variation based Membership Inference Attack (SPV-MIA). It consists of two corresponding modules: 1) large model self-correction mechanism: the large model itself is used to generate high-quality correction data sets; 2) probability fluctuation estimation method: The probability fluctuation index is proposed to describe the memory phenomenon characteristics of the large model to avoid the hypothesis of overfitting the model.
In real-world scenarios, data sets used to fine-tune large models often have extremely high privacy, so sampling high-quality correction data from the same distribution becomes a seemingly impossible challenge to integrate.
We note that large models have revolutionary fitting and generalization capabilities, enabling them to learn the data distribution of training sets and generate large amounts of creative-rich text. Therefore, large models themselves have the potential to describe the distribution of training data.
Therefore, we consider a self-cue approach to collect correction data sets from the target large model itself by prompting it with a small number of words.

△ Large model self-correcting mechanism method flow chart
Specifically, we begin by collecting a set of text blocks of length l from a public dataset in the same domain, where the domain can be easily inferred from the task of the target large model (for example, the large model used to summarize the task is fine-tuned on the summary dataset with great probability). We then use each block of text of length l as the prompt text and ask the target large model to generate the text.
All the generated text can form a data set of size N, which can be used to fine-tune the self-cue correction model. Therefore, the member inference scores corrected by the self-cue correction model can be written as: where the correction data set is sampled from the target large model:, and are the member inference scores evaluated on the target model and the correction model respectively.
The existing attack paradigm implicitly assumes that the probability of training set text being generated is higher than that of non-training set text, and this assumption is only satisfied in overfitting models.
However, fine-tuned large models in real scenes usually only have a certain degree of memory phenomenon. Although memory is associated with overfitting, overfitting alone does not fully explain some properties of memory. The key differences between memory and overfitting can be summarized in the following three points:
Therefore, the memory phenomenon is more suitable as a signal to identify the text of the training set. Memory in the generation model results in a higher generation probability for member records than neighboring records in the data distribution.

△ Differences between overfitting and memory phenomena in the model probability distribution
This principle can be shared with large models, as they can be viewed as text generation models.
Therefore, we design a more promising member inference score by determining whether the text is located at a local maximum point on the probability distribution of the target model: where is a set of symmetric text pairs sampled by the rewriting model, and this rewriting can be viewed as a small perturbation in the high-dimensional representation space of the text. In this paper, the Mask Filling Language Model (T5-base) is used to perturb the target text in semantic space and representation space respectively.
In order to evaluate the effectiveness of the attack algorithm SPV-MIA, this study conducted experimental evaluation on four open source large models GPT-2, GPT-J, Falcon-7B, LLaMA-7B and three fine-tuned datasets in different fields Wikitext-103, AG News, and XSum.
The study uses seven advanced baseline algorithms for comparison:
Comparative experiments validate the significant performance improvement of the proposed method compared with the most advanced baseline method under the above large model and fine-tuned data set, with an AUC score improvement of up to 30%.

△ Performance comparison using AUC scores (bolded for best performance, underlined for second-best performance)
From the true positive rate of 1% false positive rate (TPR@1% FPR), the improvement is as high as 260%, indicating that SPV-MIA can achieve a very high recall rate with very low false positive rate.

△ Performance comparison of true positive rate with 1% false positive rate (bolded for best performance, underlined for second-best performance)
In addition, this paper explores how correction-based member inference attack methods depend on the quality of the correction data set, and assesses whether our proposed method can build a high-quality correction data set. This experiment evaluates the performance of correction-based member inference attacks on same-distributed, same-domain, uncorrelated data sets and data sets constructed by self-cue mechanism. The experimental results show that the proposed self-cue mechanism can construct high quality data sets that are approximately identically distributed.
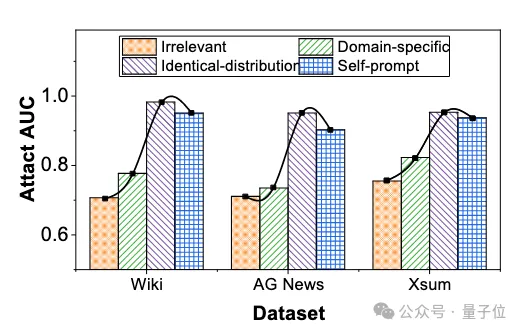
△ Performance of member inference attacks when using different correction data sets
In the real world, the sources of self-prompted text available to attackers are often limited by the actual deployment environment, and sometimes even domain-specific text cannot be obtained. And the size of the self-prompted text is usually limited by the upper limit of access frequency of the large model API and the amount of self-prompted text available. In order to further explore the robustness of SPV-MIA in complex practical scenarios, this paper explores the member inference attack performance in extreme cases from three perspectives: source, scale and length of self-cue text.
The experimental results show that for different sources of prompt text, the self-prompt method has an incredibly low dependence on the source of prompt text. Even with completely unrelated prompt text, there was only a slight drop in attack performance (up to 3.6%). Therefore, the self-prompting method has strong universality in front of attackers with different prior information.
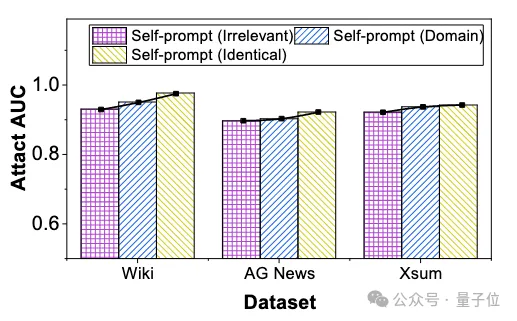
△SPV-MIA attack performance under different source self-prompting text
And the self-prompt method has very little impact on query frequency, requiring only 1,000 queries to achieve an AUC score close to 0.9. In addition, a self-prompt text with only 8 tokens can also guide a large model to generate a high-quality correction model.
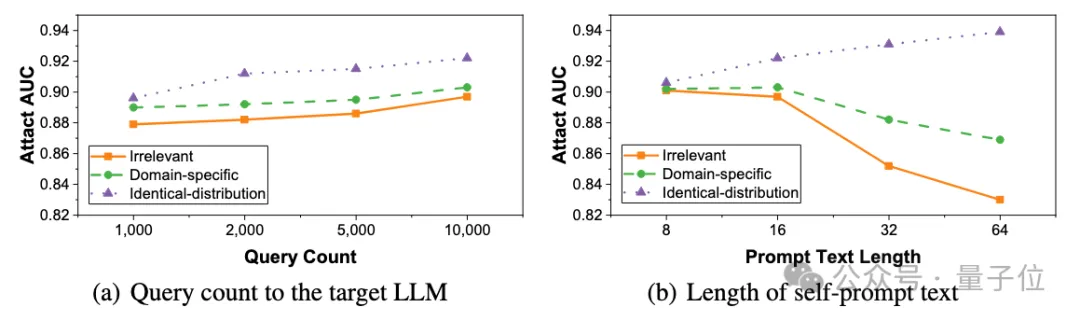
△SPV-MIA attack performance under different scales and lengths of self-prompting text
This paper first reveals from two angles that the existing member inference attacks can not cause effective privacy disclosure risks to fine-tuning large models in real scenarios. To solve these problems, we propose a member inference attack based on self-correcting probability fluctuations (SPV-MIA), in which we propose a self-cue method that achieves the extraction of corrected data sets from large language models in real-world scenarios, and then introduce a more reliable member inference score based on memory rather than overfitting. We conducted a number of experiments to demonstrate the superiority of SPV-MIA over all baselines and to verify its effectiveness under extreme conditions.
The thesis links: https://openreview.net/forum?id=PAWQvrForJ.
Code link: https://github.com/tsinghua-fib-lab/NeurIPS2024_SPV-MIA.

2025-02-17

2025-02-14

2025-02-13

抖音二维码


微信公众号

QQ群:

小红书二维码
13004184443
Room 607, 6th Floor, Building 9, Hongjing Xinhuiyuan, Qingpu District, Shanghai
gcfai@dongfangyuzhe.com

WeChat official account
friend link


13004184443
立即获取方案或咨询
top







