
Home > Information > News
#News ·2025-01-03



Translator | Bugatti
Review | heavy building
Imagine driving a car with headphones that update the road every five minutes, instead of providing a constant video stream of your current location. It won't be long before you crash.
Although this type of batch processing is not applicable in the real world, it is the way many systems operate today. Batch processing was born out of outdated technical limitations that forced applications to rely on static, delayed data. This approach may be the only viable solution when computing, memory, and storage are limited, but it is completely at odds with the way we interact with the real world, much less the way AI works.
Generative AI has incredible potential, and large language models (LLMS) cannot be seen as static databases, reactive systems that wait for inputs and provide outputs. AI relies on real-time situational data to thrive. If we cling to the batch concept, we are killing its capabilities.
Discuss why the batch paradigm is obsolete, how it has hindered the development of AI applications, and why the future of AI requires a real-time event streaming platform.
Batch-oriented systems for analytics and machine learning have dominated the technology world for decades. These systems came into being and were created at a time when computer memory was limited, computing power was limited, and storage space was minimal. However, the same traditional methods are now being applied to the new era of generative AI.
Machine Learning Operations (MLOps) has largely evolved around a discrete, sequential set of tasks, such as feature engineering, model training, model testing, model deployment, and bias characterization. This conceptual model is well suited for batch-oriented development and delivery, but it limits the reactivity and accuracy of these applications in a changing world. Applications that need to be more responsive will inevitably need to avoid the generic MLOps infrastructure.
In our view, this is a flawed approach.
At its core, this paradigm aggregates data into a central database that passively waits for the system or user to poll and call. The purpose of the resulting system depends entirely on the specific needs of the query received. While this approach worked for the constraints of the time, it was fundamentally divorced from the way we experience and interact with the world.
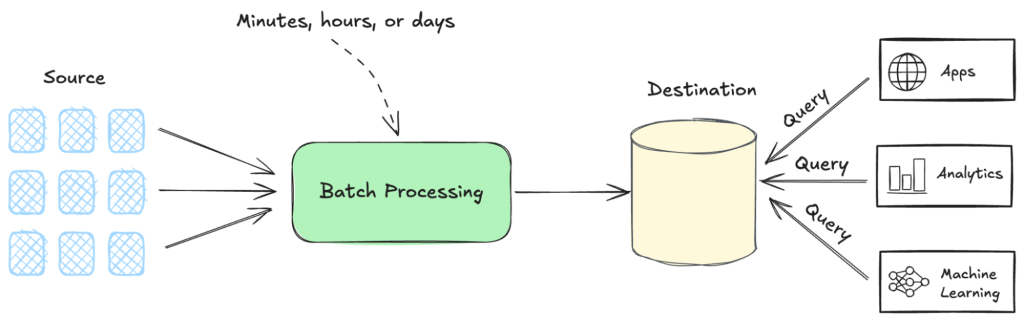
Figure 1. General diagram of batch process
Despite advances in technology, this belief remains deeply rooted. Today, we have alternative technologies such as data streaming platforms that enable real-time, event-driven architectures. But batch systems still exist, not because they are the best solution, but because they have become the accepted way of doing things.
Just like the old saying "no one gets fired for buying an IBM system", the same is true of batch systems: no one gets fired for designing a system that aggregates data in one place, provided that acting on this centralized data is efficient and reliable. We are used to thinking of work as a series of tasks, one completed before the next. Mature results from disciplines such as operations research and lean manufacturing show that we excel at doing batch work because we get better through practice, and switching minds is less efficient. Modern distributed systems need not be constrained by our limitations.
In our daily lives, we don't deal with the world based on "batch updates." We are constantly processing information, reacting and adapting to changing situations. However, historical limitations caused batch processing to become the default paradigm.
Traditional machine learning reflects this batch-oriented thinking. The model operates around a strict linear workflow:
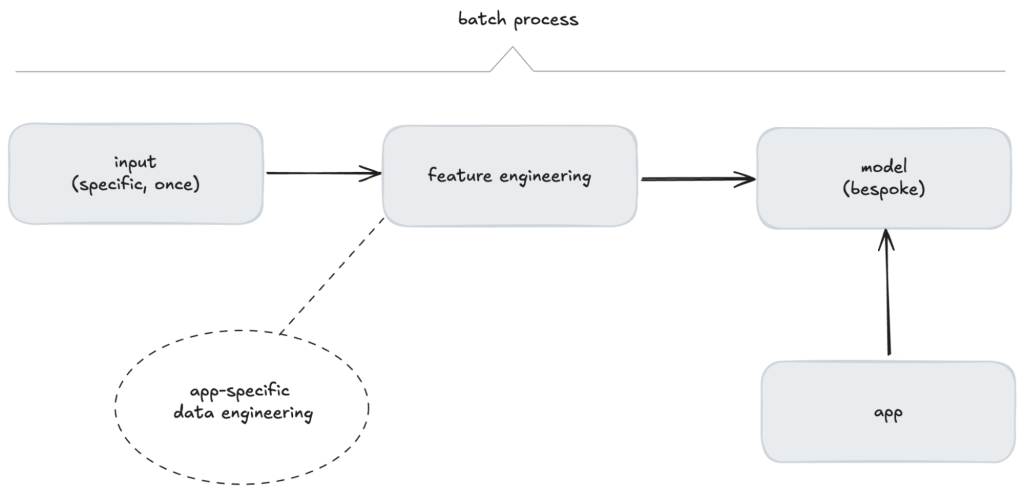
Figure 2. Batch flow of traditional machine learning
While this process works well for specific use cases, it is inherently rigid and inflexible.
By contrast, one of the reasons generative AI is so transformative is because the underlying model is inherently reusable and capable of solving a variety of problems across many domains. However, in order for these models to be reusable between different domains, it is necessary to ensure that the data is in a specific scenario during prompt assembly, and batch processing does not meet this requirement.
Consider a simple example. Imagine we develop an AI-based flight assistant to help customers when their flights are delayed.
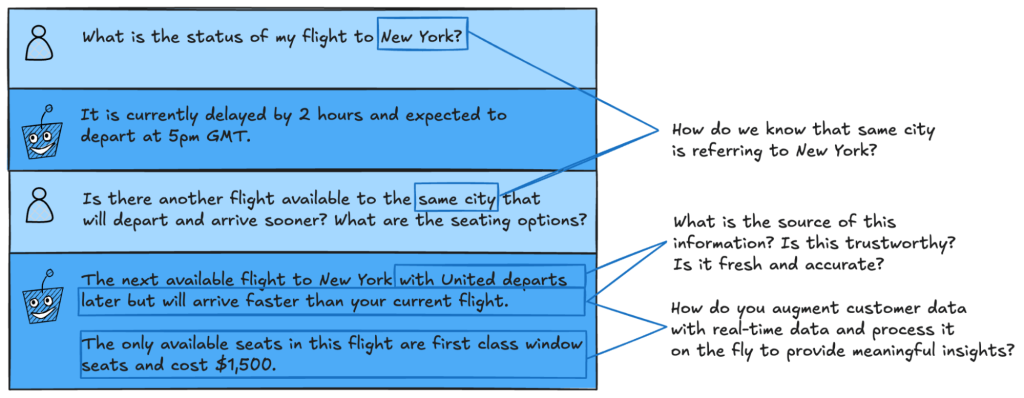
Figure 3. Sample interaction between a user and an AI flight assistant
In the two rounds of interaction above, a lot of situational information is needed to satisfy the customer's requirements.
The LLM needs to remember that the relevant city is New York. It needs to know the customer's identity and current booking status, current flight information, departure/arrival times, seat layout, seat preferences, pricing information, and airline change policies.
Unlike traditional machine learning, where models are trained with application-specific data, LLM doesn't train with your data, they train with general information. Data engineering for a specific application occurs during prompt assembly, not during model creation.
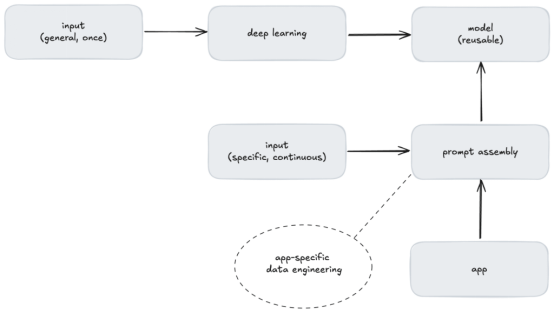
Figure 4. LLM reusability and customization through prompt assembly
At a time when two medical papers are published every minute and 8,400 legal cases are resolved every hour, static data is not enough. AI systems need data flowing in real time to come up with solutions. Despite better options, sticking with batch-oriented systems limits the potential for modern applications, especially in AI. It's time to rethink this outdated approach and embrace architectures that reflect how we live and work in a dynamic, real-time world.
When we design the next generation of AI applications, we may fall into the same batch-oriented trap. We think of LLMS as databases (responsive tools that wait for input and respond to specific queries). But this perception simply does not match the capabilities of the LLM. AI isn't just for preserving information, it's for reasoning, generation, and evolution.
Databases are inward-looking, holding information and only making it available when explicitly requested, whereas LLMS are outward-looking, aiming to participate, synthesize, and actively contribute. They are suitable for environments where application scenarios are constantly changing and architectures that can support this dynamic behavior. A batch-oriented approach (where models and data are updated regularly, but otherwise static) stifles the true potential of generative AI.
To truly realize AI's potential, we need to shift our thinking.
AI systems should be active participants in the workflow - contributing ideas, engaging in dynamic conversations, and in some cases operating autonomously. This requires a significant change in the architecture. Instead of a static query-response system, we need an event-driven architecture that enables smooth real-time interactions and ADAPTS flexibly.
The data flow platform supports real-time requirements, that is, supports continuous, event-driven workflows to meet dynamic and fast-paced system requirements. In areas such as finance, telecommunications, and e-commerce, where milliseconds make or break, batch-oriented architectures fall short. Applications are needed to detect fraud while a transaction is in progress, update inventory when a product is sold, or provide real-time personalization during a customer interaction.
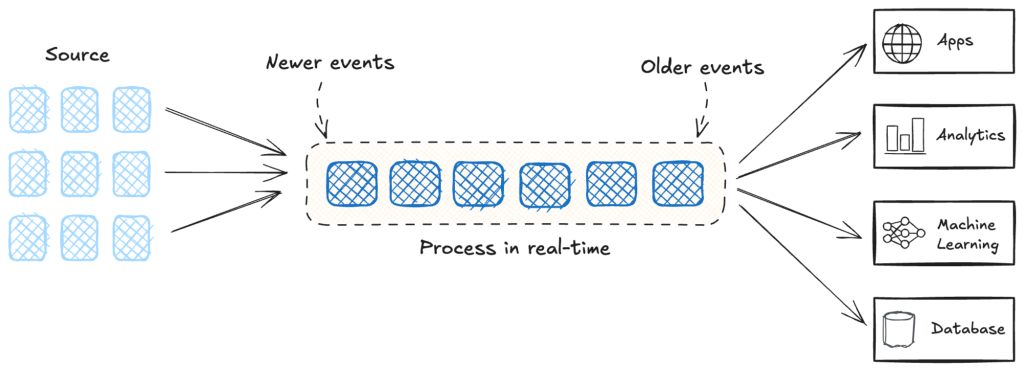
Figure 5. General diagram of flow processing
Most practical use cases for generative AI rely on real-time situational data. Stream processing platforms complement these models by overcoming significant challenges that batch processing systems cannot address.
The rise of agent AI has sparked interest in agents that are not limited to simple query/response interactions. Such systems can initiate actions autonomously, make decisions, and adapt to changing circumstances.
Consider a typical AI agent. We can think of agents as automated processes that reason about their environment and take proactive action to achieve some specified goal. Its decisions can be complex and include conditional branching logic that is affected by intermediate data queries.
It may require pulling data from multiple sources, handling prompt engineering and RAG workflows, and interacting directly with various tools to perform deterministic and random workflows. The required orchestration is complex and depends on multiple systems. If agents need to communicate with other agents, the complexity will only increase. Without a flexible architecture, these dependencies make extension and modification almost impossible.
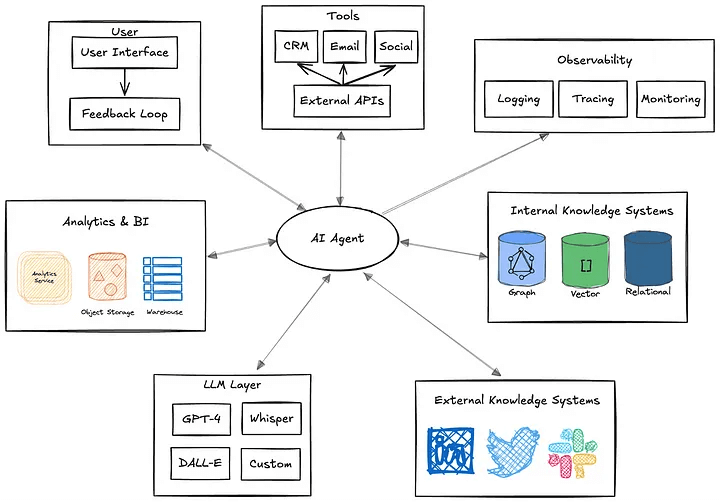
Figure 6. Proxy dependency profile
To do this, they need to:
For example, AI-based travel assistants using stream processing can automatically monitor flight schedules, identify delays, rebook affected flights, and notify users, all without human intervention. With static data that is updated in batches, this level of autonomy is not possible.
Stream processing platforms address these needs by providing continuous, low-latency data streams and the infrastructure essential for real-time computing. Without this foundation, autonomous, collaborative AI systems remain a distant dream.
Generative AI is a fundamental shift in the way we build and use technology. To realize its full potential, we need systems that align with the way AI processes and gains insights: continuously, dynamically, and in real time. Stream processing platforms provide the basis for this evolution.
If we integrate AI applications with stream processing platforms, we can:
Generative AI isn't just about building smarter systems, it's about building a continuous, ever-changing stream of events. Stream processing platforms make all of this possible, bridging the gap between the static systems of yesteryear and the dynamic AI-based future.
Stop Treating Your LLM Like a Database, by Sean Falconer

2025-02-17

2025-02-14

2025-02-13

抖音二维码


微信公众号

QQ群:

小红书二维码
13004184443
Room 607, 6th Floor, Building 9, Hongjing Xinhuiyuan, Qingpu District, Shanghai
gcfai@dongfangyuzhe.com

WeChat official account
friend link


13004184443
立即获取方案或咨询
top







