
Home > Information > News
#News ·2025-01-03


In today's rapidly changing AI technology, large-scale language models have become an important force to promote the development of AI. On December 26, 2024, DeepSeek AI officially released its latest large-scale language model, Deepseek-V3. The open source model uses a Hybrid Expert (MoE) architecture of up to 671 billion parameters and is capable of processing 60 tokens per second, which is three times faster than V2. Once released, it caused an uproar in the field of AI.
It is worth noting that DeepSeek-V3 not only supports GPU training and inference, but also supports the Shengteng platform upon release, achieving efficient inference on Shengteng hardware and MindIE inference engine, providing users with more options for computing hardware.
With GPT-4o neck and neck, China's large model leading the world
Deepseek-v3 is a Mixture of Experts (MoE) language model with 671 billion total parameters and 37 billion parameters per token activation, published by artificial intelligence company DeepSeek. It inherits the core architecture of DeepSeek-V2 with a number of innovations that significantly improve the performance and efficiency of the model.
DeepSeek-V3 uses an innovative knowledge distillation method to transfer the reasoning capabilities in the DeepSeek R1 series models to the standard LLM, significantly improving the reasoning performance of the models.
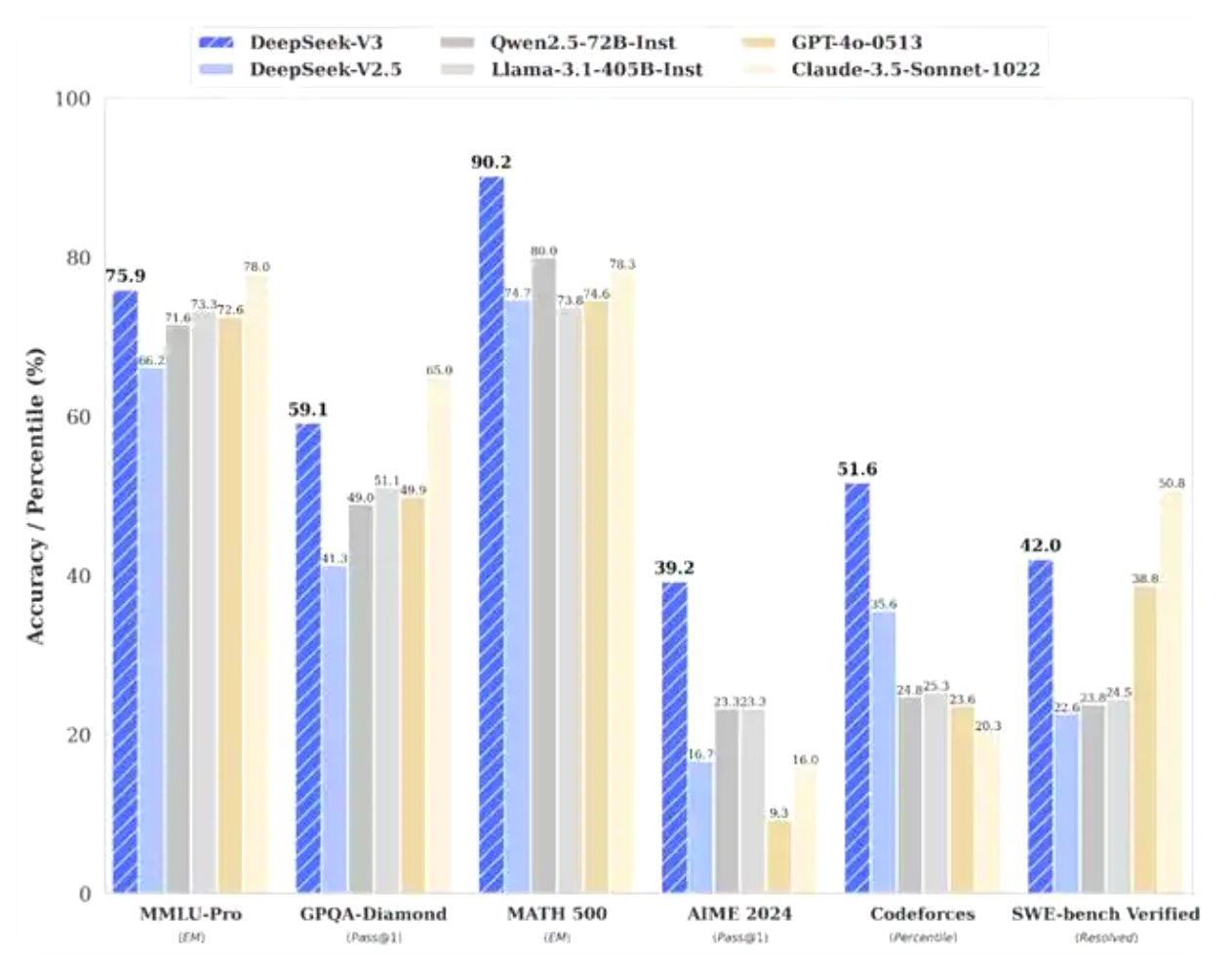
According to the test results published by DeepSeek, which ran a number of benchmarks to compare performance, the V3 model has significantly outperformed leading open source models including Meta's Llama-3.1-405B and Alibaba Cloud's Qwen 2.5-72B. In most benchmarks, it even partially outperforms OpenAI's closed-source model GPT-4o.
According to data published by DeepSeek, V3's level of knowledge tasks is significantly improved compared to its predecessor DeepSeek-V2.5, and is close to the current best-performing model, Claude-3.5-Sonnet-1022, released by Anthropic in October. In the American MATH Competition (AIME 2024, MATH) and the National High School Math League (CNMO 2024), DeepSeek-V3 outperformed all other open source closed-source models by a wide margin. In terms of generation speed, the generation speed of DeepSeek-V3 has been greatly increased from 20TPS to 60TPS, which is 3 times higher than the V2.5 model, and can bring a more smooth use experience.
The DeepSeek-V3 model verified the feasibility and effectiveness of FP8 training on a large-scale model for the first time, and effectively overcame the communication bottleneck in cross-node MoE training through collaborative optimization. Therefore, DeepSeek-V3 achieved a great reduction in training costs while maintaining high performance. According to DeepSeek officials, the training cost of the model is only $5.576 million, far less than the hundreds of millions of dollars of training costs of similar models.
As an open source grand model, DeepSeek-V3 supports the native deployment of multiple open source frameworks, including SGLang, LMDeploy, and TensorRT-LLM, providing developers with a wealth of options. At the same time, DeepSeek-V3 also supports more inference engines, providing users with more choices of computing products, and promoting the innovation and development of China's AI industry.
Native support for Centeng AI, to provide users with more computing product choices
DeepSeek-V3 not only makes a major breakthrough in technology, but also implements native support for more inference engines. Taking the Censor platform as an example, DeepSeek-V3 is released to support the Censor platform, allowing users to achieve efficient reasoning on Censor hardware and MindIE inference engine, providing domestic users with an integrated solution of hardware and software.
On the Magle community, the deployment mode of implementing DeepSeek-V3 model inference on Center hardware and MindIE inference engine has been released. Users can optimize service framework according to the operation manual, monitor operation and maintenance, specify NPU card, start multiple instances on a single machine, etc., optimize service performance and customize the operating environment. Give full play to the computing power of Shengteng hardware equipment to improve the efficiency of model reasoning. (Click for detailed deployment)
As Centen's reasoning engine for AI full-scene services, MindIE has shown significant advantages in communication acceleration, decoding optimization, quantization compression, optimal parallelism, and scheduling optimization.
First, MindIE enables fast communication between the business layer and the inference engine through an efficient RPC (Remote Procedure Call) interface. This interface supports mainstream inference service frameworks such as Triton and TGI, making application deployment easier and possible in less than an hour.
 Communication acceleration diagram
Communication acceleration diagram
Second, in terms of decoding optimization, MindIE provides accelerated reference code and preset models for specific application scenarios such as LLM (Large Language Model) and Vincennes graph (SD model). These optimizations enable MindIE to generate inference results faster during the decoding phase, improving overall performance. Especially for large model reasoning, MindIE supports acceleration characteristics such as Continuous Batching, PageAttention and FlashDecoding, which further improves the reasoning efficiency.
 Decoding optimization diagram
Decoding optimization diagram
In terms of quantization compression, the quantization methods in MindIE are based on industry-leading quantization techniques such as SmoothQuant, AWQ, etc., which are able to significantly reduce model size and computation while maintaining model accuracy.
 Quantized compression diagram
Quantized compression diagram
In addition, MindIE provides an optimal parallel strategy to take full advantage of hardware resources such as multi-core processors and Gpus. When it comes to parallel computing, MindIE supports strategies such as Tensor Parallelism, which enables models to run in parallel on multiple processor cores for faster inference. Through the optimal parallel strategy, MindIE can achieve higher inference performance while maintaining model accuracy and stability.
 Schematic diagram of optimal parallel strategy
Schematic diagram of optimal parallel strategy
In terms of scheduling optimization, MindIE provides the scheduling function of multiple concurrent requests, which can deal with a large number of concurrent requests efficiently. In addition, MindIE supports unified memory pool management of KV caches, which reduces memory fragmentation and access latency and improves memory utilization. In the aspect of task scheduling, MindIE realizes user request group batch based on scheduling policy. Through reasonable task allocation and scheduling, resources are fully utilized and the overall performance is improved.
 Scheduling optimization two-stage hybrid scheduling decoding diagram
Scheduling optimization two-stage hybrid scheduling decoding diagram
Because DeepSeek-V3 can nately support the ascension hardware and MindIE Ascension inference engine, it makes it easier for users to deploy and use the DeepSeek-V3 model, further promoting the wide application of AI technology in various fields.
Accelerate the innovation and development of AI technology, and usher in new opportunities for China's large model
51CTO believes that the success of DeepSeek-v3 not only demonstrates China's strength in AI innovation, enhances the status of China's large model in global science and technology competition, but also lowers the threshold for the development of large models, promotes the development of China's AI hardware and software industry, and comprehensively promotes the innovation and development of AI technology.
First of all, DeepSeek-V3 fully demonstrated China's strength in AI innovation, enhancing the position of China's big model in the global science and technology competition. With the success of DeepSeek-V3, more and more international attention will focus on the Chinese AI field, and strive for more cooperation opportunities and market space for Chinese companies.
Second, DeepSeek-V3's open source strategy and API pricing strategy have lowered the application threshold of AI technology and promoted technology sharing and cooperation within the industry. The open source DeepSeek-V3 not only promotes the sharing and exchange of AI technology, but also further lowers the application threshold in the industry, providing a more affordable choice for developers and enterprises.
In addition, the success of DeepSeek-V3 also provides an example of China's large model in the vertical field. DeepSeek-V3 can be applied to smart home, intelligent customer service, security, medical, writing assistance and other scenarios, which provides a broad space and unlimited possibilities for the development of China's large model in the vertical field.
Finally, DeepSeek-V3 will help build a more complete AI ecosystem by supporting more inference engines. Through close cooperation with more inference engines, DeepSeek-v3 can better adapt to the needs of domestic users and promote the popularization and application of AI technology in China.
In SUMMARY:
The success of DeepSeek-V3 not only demonstrates China's innovative strength in the field of AI, but also brings unprecedented new opportunities for the future development of China's large model. With the continuous progress of technology and the continuous expansion of application scenarios, China's big model will play an increasingly important role in the global science and technology competition, bringing more convenience and fun to people's lives.
Looking to the future, with the continuous expansion of artificial intelligence technology application scenarios, the AI industry will usher in a broader space for development. The success of DeepSeek-V3 is only the beginning, and China's large model will continue to achieve new breakthroughs under the impetus of technological progress and wide application. To this end, we have reason to believe that China's big model can continue to innovate and progress in the future development, and contribute more Chinese wisdom and strength to the future development of global AI technology.

2025-02-17

2025-02-14

2025-02-13

抖音二维码


微信公众号

QQ群:

小红书二维码
13004184443
Room 607, 6th Floor, Building 9, Hongjing Xinhuiyuan, Qingpu District, Shanghai
gcfai@dongfangyuzhe.com

WeChat official account
friend link


13004184443
立即获取方案或咨询
top







