#新闻 ·2025-01-09


译者 | 布加迪
审校 | 重楼
近年来,我们见证了两个反复出现的趋势:发布的GPU功能越来越强大,以及拥有数十亿、乃至数万亿个参数和加长型上下文窗口的大语言模型(LLM)层出不穷。许多企业正在利用这些LLM,或进行微调,或使用RAG构建具有特定领域知识的应用程序,并将其部署在专用GPU服务器上。现在说到在GPU上部署这些模型,需要注意的一点是模型大小,即相比GPU上的可用内存,将模型加载到GPU内存中所需的空间(用于存储参数和上下文token)实在太大了。
有一些方法可以通过使用量化、修剪、蒸馏和压缩等优化技术来缩减模型大小。但是如果你注意到下面70B模型(FP16量化)的最新GPU内存和空间需求的比较表,几乎不可能同时处理多个请求,或者在一些GPU中,模型甚至无法装入到内存中。
GPU | FP16(TFLOPS) 带稀疏性 | GPU内存(GB) |
B200 | 4500 | 192 |
B100 | 3500 | 192 |
H200 | 1979 | 141 |
H100 | 1979 | 80 |
L4 | 242 | 24 |
L40S | 733 | 48 |
L40 | 362 | 48 |
A100 | 624 | 80 |
这都是已经运用的FP16量化,导致一些精度损失(这在许多普通的用例中通常是可以接受的)。
模型 | 参数所需的KV缓存(FP16) |
Llama3-8B | 16GB |
Llama3-70B | 140GB |
Llama-2-13B | 26GB |
Llama2-70B | 140GB |
Mistral-7B | 14GB |
这就引出了这篇博文的背景,即企业如何在这些现代数据中心GPU上运行数十亿或万亿个参数的大型LLM模型。是否有办法将这些模型分割成更小的部分,只运行眼下所需的部分?或者我们是否可以将模型的部分分配到不同的GPU上?在这篇博文中,我将尝试用当前可用于执行推理并行的一系列方法来回答这些问题,并尝试重点介绍一些支持这些并行方法的工具/库。
推理并行(Inference Parallelism)旨在将AI模型(特别是深度学习模型)的计算工作负载分配到多个处理单元(如GPU)上。这种分配可以加快处理、缩短延迟以及能够处理超出单个设备内存容量的模型。
现已开发出了四种主要的方法来实现推理并行,每种方法都有其优势和应用:
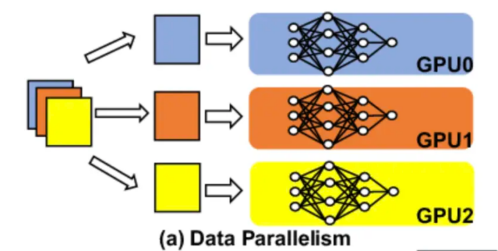
在数据并行方面,我们在不同的GPU或GPU集群上部署模型的多个副本。模型的每个副本都独立处理用户请求。打个简单的比方,这好比拥有一个微服务的多个副本。
现在,一个常见的问题可能是它如何解决模型大小装入到GPU内存中的问题,简短的回答是装不了。该方法仅推荐给可以装入到GPU内存中的较小模型。在这种情况下,我们可以使用部署在不同GPU实例上的模型的多个副本,并将请求分配到不同的实例,从而为每个请求提供足够的GPU资源,还增加服务的可用性。这还将为系统提升总体请求吞吐量,因为现在有更多的实例来处理流量。
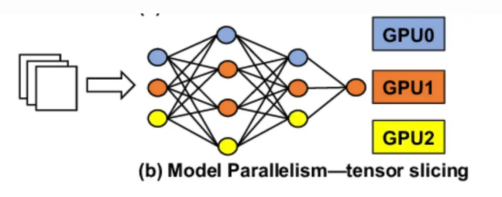
在张量并行方面,我们将模型的每一层分割到不同的GPU上。单个用户请求将跨多个GPU共享,每个请求的GPU计算的结果则通过GPU到GPU的网络重新组合。
为了更好地理解张量并行,顾名思义,我们沿着特定的维度将张量分割成几块,这样每个设备只容纳张量的1/N块。使用这个部分块执行计算以获得部分输出。这些部分输出从所有设备收集而来,然后组合。
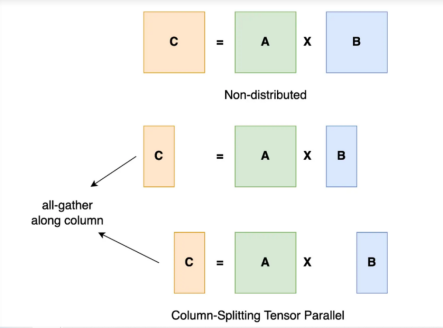
你可能已经注意到了,张量并行性能上的瓶颈是GPU到GPU之间的网络速度。由于每个请求将在不同的GPU上进行计算然后组合,因此我们需要高性能网络来确保低延迟。
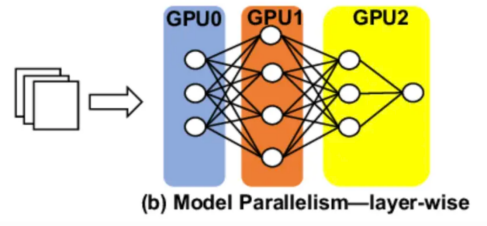
在管道并行方面,我们将一组模型层分配到不同的GPU上。基于层的划分是管道并行中的基本方法。模型的层被分组成连续的块,形成阶段(Stage)。这种划分通常通过网络的架构纵向进行。计算平衡是一个关键的考虑因素。理想情况下,每个阶段都应该有大致相等的计算负载,以防止瓶颈。这通常需要对不同复杂性的层进行分组以达到平衡。内存使用优化是另一个关键因素。阶段旨在符合单个设备的内存限制,同时最大限度地提高利用率。尽量降低通信开销也很重要。划分的目的是减少各阶段之间传输的数据量,因为设备间通信可能是一个严重的性能瓶颈。
所以比如说,如果你在4个GPU的实例上部署有32层的LLaMA3-8B模型,可以在每个GPU上分割和分配模型的8层。请求的处理按顺序进行,计算从一个GPU开始,并通过点对点通信继续到下一个GPU。
同样,由于涉及多个GPU实例,如果我们在GPU之间没有高速网络通信,网络可能成为一大瓶颈。这种并行可以增加GPU的吞吐量,因为每个请求将需要来自每个GPU的更少资源,应该很容易获得,但它最终会增加总体延迟,因为请求按顺序处理,任何GPU计算或网络部件方面的延迟都会导致延迟总体激增。
专家并行常常作为专家混合(MoE)来实现,这种技术允许在推理过程中高效使用大模型。它没有解决将模型装入到GPU内存中的问题,但提供了一个基于请求上下文处理请求的广泛功能模型的选项。在该技术中,模型被划分为多个专家子网。每个专家通常都是经过训练的神经网络,用于处理更广泛的问题领域内特定类型的输入或子任务。门控网络决定对每个输入使用哪个专家。对于任何给定的输入,只有一部分专家被激活。不同的专家可以分配到不同的GPU上。路由器/门控网络和活跃的专家可以并行运行。不活跃的专家不消耗计算资源。这大大减少了每个请求必须与之交互的参数数量,因为一些专家被跳过。但与张量并行和管道并行一样,总体请求延迟严重依赖GPU到GPU的通信网络。在专家处理后,请求必须重新构造回到其原始GPU,通过GPU到GPU互连结构构成高网络通信。
与张量并行相比,这种方法可以更好地利用硬件,因为你不必将操作分割成更小的块。
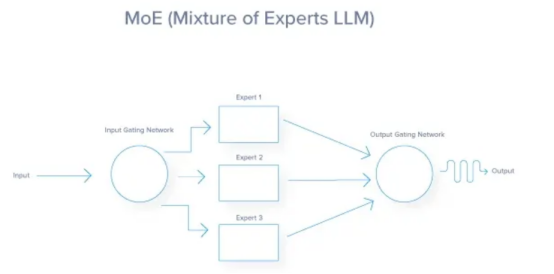
下面总结和比较了我们讨论的几种方法。当你计划为自己的用例选择一种方法时,可以使用它作为参考。
方面 | 数据并行 | 张量并行 | 管道并行 | 专家并行 |
基础概念 | 在多个设备上分割输入数据 | 在设备上分割单个张量/层 | 在设备上将模型分割成多个顺序阶段 | 将模型分割成多个专家子网络 |
工作原理 | 同一模型复制到每个设备上,处理不同数据块 | 单个层/操作分配到多个设备上 | 模型管道的不同部分在不同设备上 | 路由器为每个输入选择特定的专家 |
并行单位 | 输入批量 | 单个张量/层 | 模型阶段 | 专家(子网络) |
可扩展性 | 相对批量大小而言,扩展性良好 | 对超大模型而言,扩展性良好 | 对深度模型而言,扩展性良好 | 对宽模型而言,扩展性良好 |
内存效率 | 低(每个设备上 有标准模型) | 高(每个设备上 只有每个层的 一部分) | 高(每个设备上 只有模型的一部 分) | 中到高(专家分配在设备上) |
通信开销 | 低 | 中到高 | 低(只有邻近Stages 之间) | 中(路由器通信
如有任何疑问 请随时与我们联系 友情链接
|




















